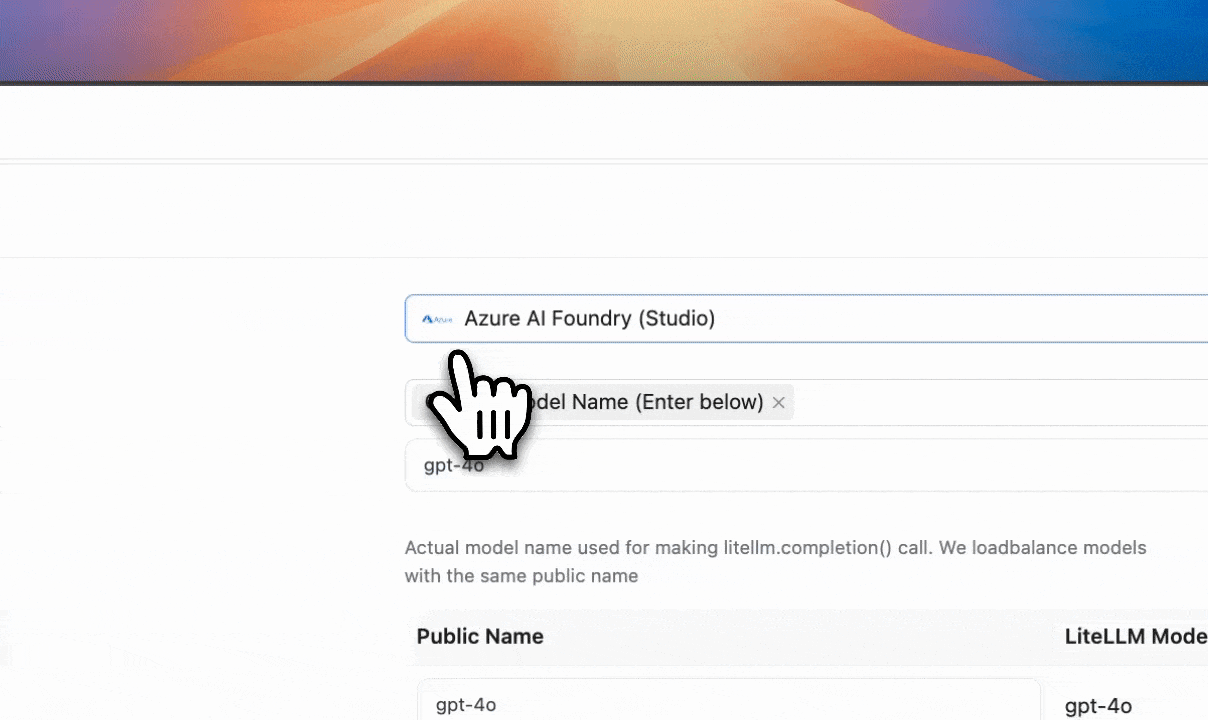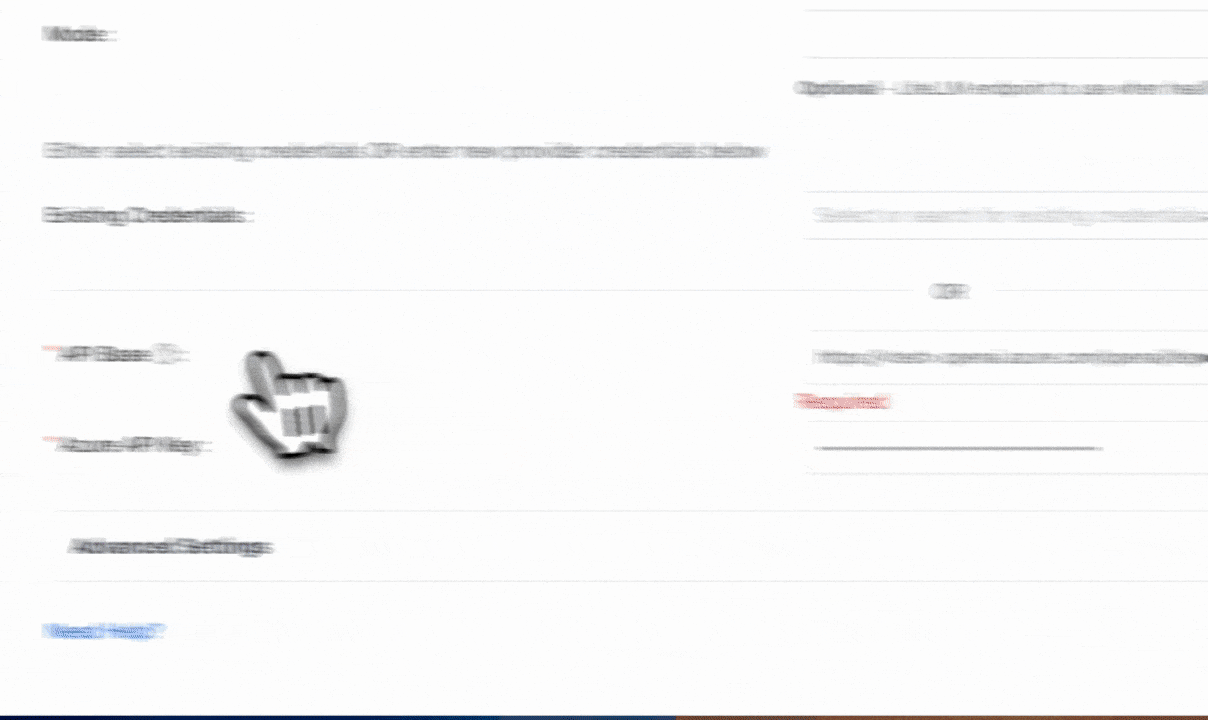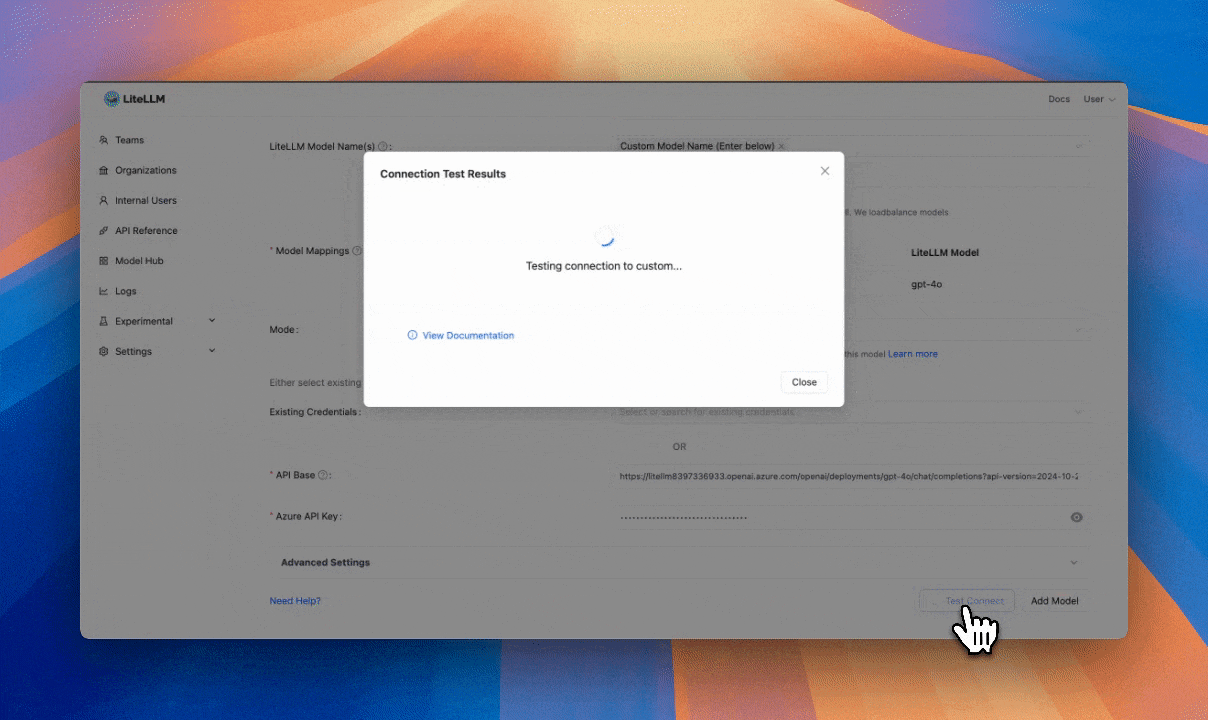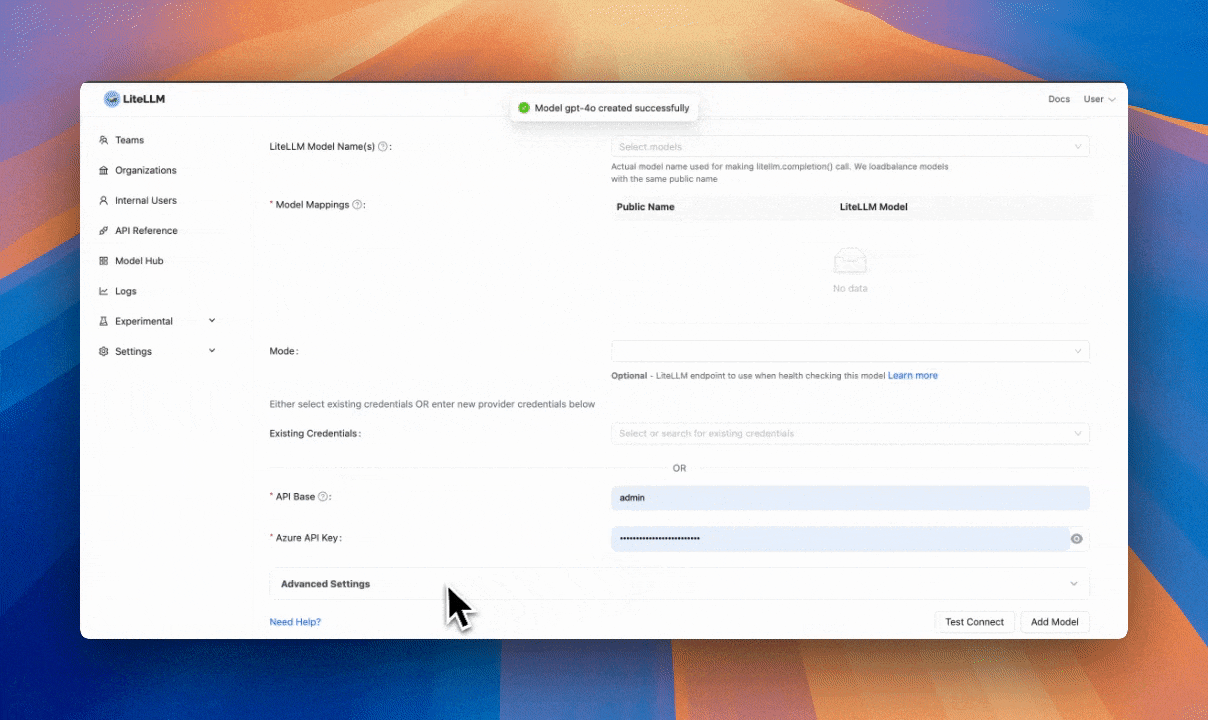
Deploy this version
- Docker
- Pip
docker run litellm
docker run
-e STORE_MODEL_IN_DB=True
-p 4000:4000
ghcr.io/berriai/litellm:main-v1.68.0-stable
pip install litellm
pip install litellm==1.68.0.post1
New Models / Updated Models
- Gemini (VertexAI + Google AI Studio)
- VertexAI
- Bedrock
- Image Generation - Support new ‘stable-image-core’ models - PR
- Knowledge Bases - support using Bedrock knowledge bases with
/chat/completionsPR - Anthropic - add ‘supports_pdf_input’ for claude-3.7-bedrock models PR, Get Started
- OpenAI
- 🆕 LlamaFile provider PR
LLM API Endpoints
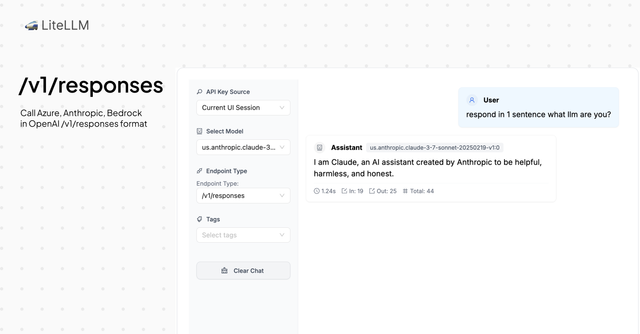
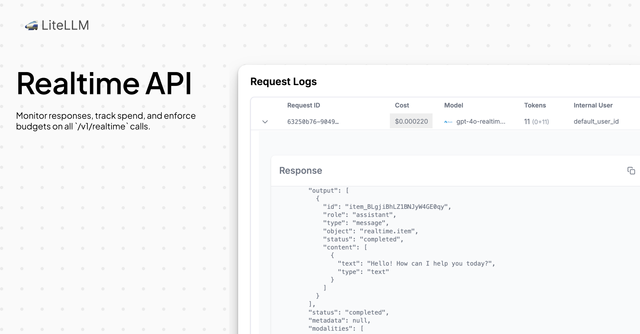
- Response API
- Fix for handling multi turn sessions PR
- Embeddings
- Caching fixes - PR
- handle str -> list cache
- Return usage tokens for cache hit
- Combine usage tokens on partial cache hits
- Caching fixes - PR
- 🆕 Vector Stores
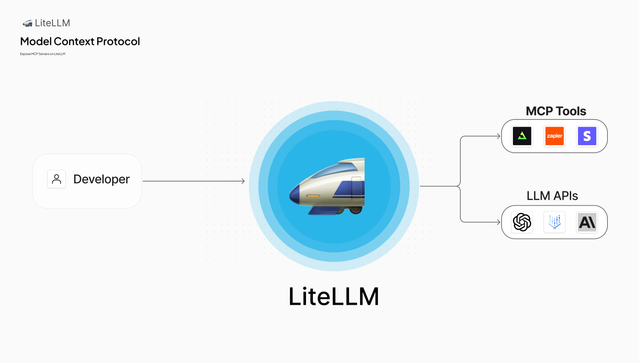
- MCP
- Moderations
- Add logging callback support for
/moderationsAPI - PR
- Add logging callback support for
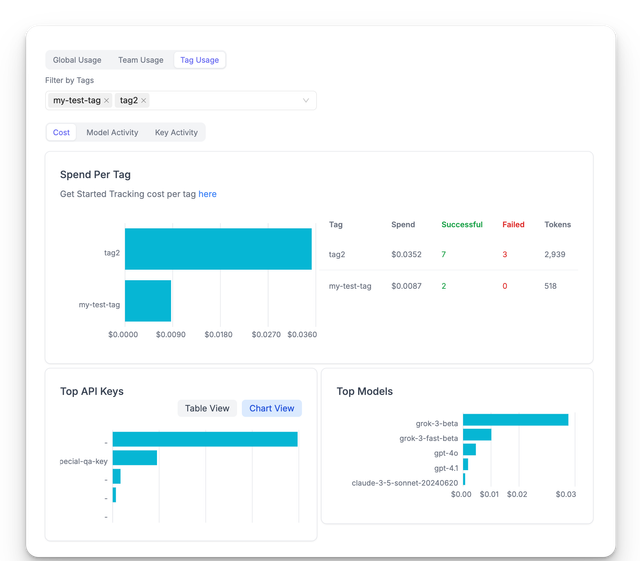
Spend Tracking / Budget Improvements
- OpenAI
- computer-use-preview cost tracking / pricing PR
- gpt-4o-mini-tts input cost tracking - PR
- Fireworks AI - pricing updates - new
0-4bmodel pricing tier + llama4 model pricing - Budgets
- Budget resets now happen as start of day/week/month - PR
- Trigger Soft Budget Alerts When Key Crosses Threshold - PR
- Token Counting
- Rewrite of token_counter() function to handle to prevent undercounting tokens - PR
Management Endpoints / UI
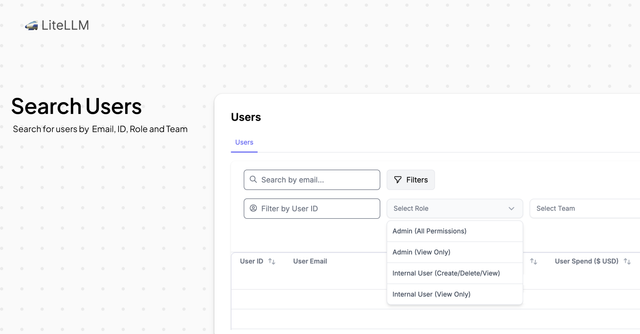
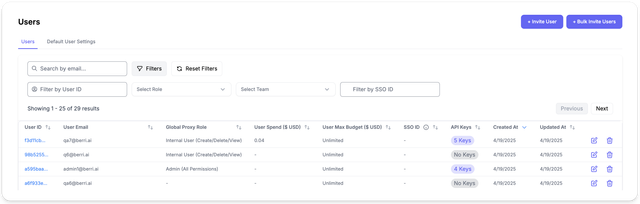
- Virtual Keys
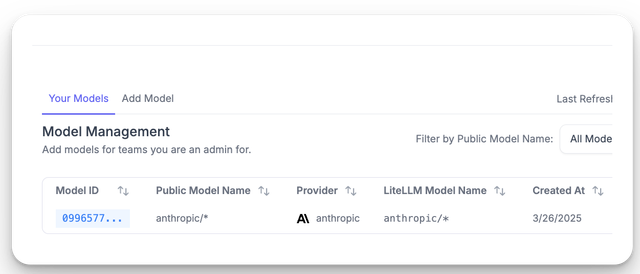
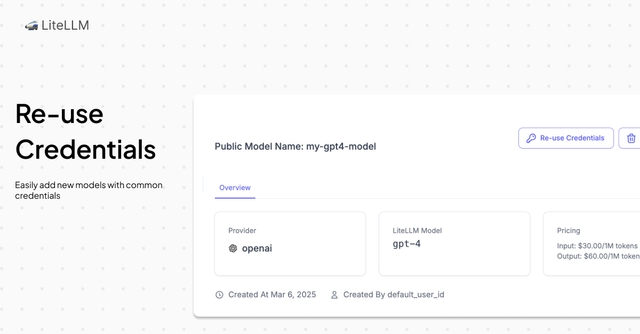
- Models
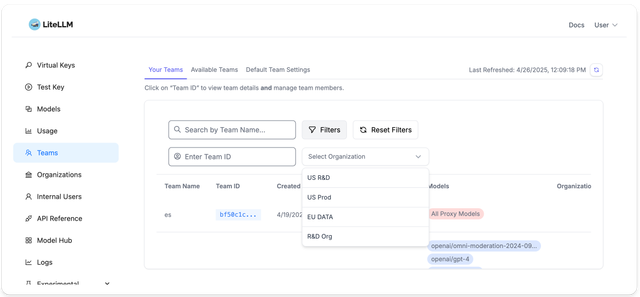
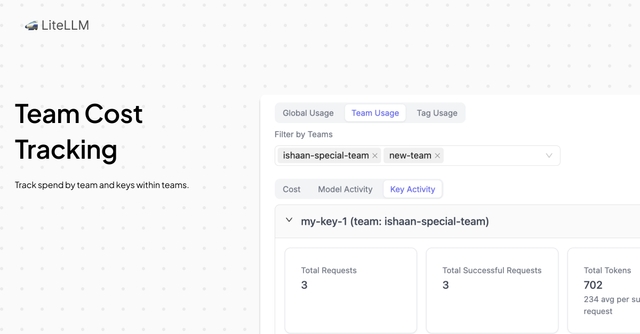
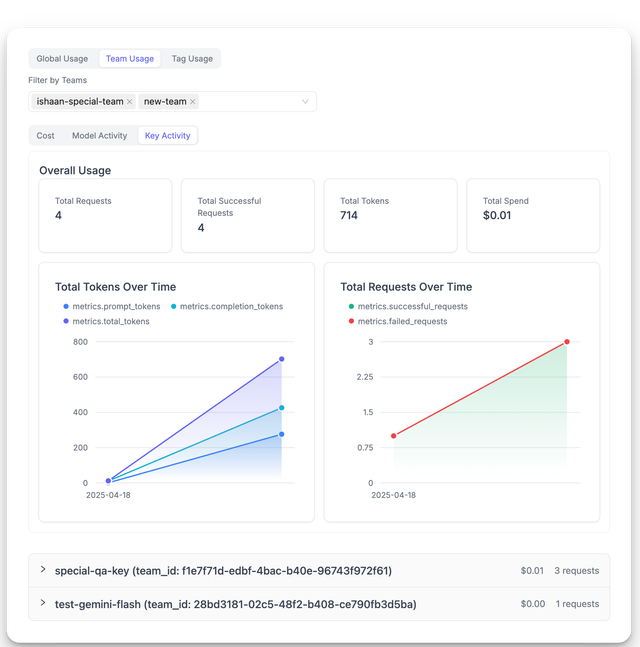
- Teams
- Allow reassigning team to other org - PR
- Organizations
- Fix showing org budget on table - PR
Logging / Guardrail Integrations
- Langsmith
- Respect langsmith_batch_size param - PR
Performance / Loadbalancing / Reliability improvements
- Redis
- Ensure all redis queues are periodically flushed, this fixes an issue where redis queue size was growing indefinitely when request tags were used - PR
- Rate Limits
- Multi-instance rate limiting support across keys/teams/users/customers - PR, PR, PR
- Azure OpenAI OIDC
General Proxy Improvements
- Security
- Allow blocking web crawlers - PR
- Auth
- Support
x-litellm-api-keyheader param by default, this fixes an issue from the prior release wherex-litellm-api-keywas not being used on vertex ai passthrough requests - PR - Allow key at max budget to call non-llm api endpoints - PR
- Support
- 🆕 Python Client Library for LiteLLM Proxy management endpoints
- Dependencies
- Don’t require uvloop for windows - PR